

개론
인덱싱의 기본적인 방법들, heap, hash, sorted file 들은 일장일단의 성격을 지니고 있다.
그런데 모든 부분에서 두루두루 성능이 좋게 나오는 인덱싱 기법은 없는걸까?
모든 면에서 성능이 좋은 인덱싱 기법은 없지만 적절한 성능을 내는 기법은 있다.
바로 B+ Tree이다.
하지만 이번 포스트에선 B+ Tree가 무엇인지 알아보기 전에 B+ Tree의 이전 형태인 B Tree를 보자.
특징
1. 노드에는 2개 이상의 데이터(key)가 들어갈 수 있고, 이들은 항상 정렬된 상태로 구성된다.▼

2. 내부 노드(루트노드와 리프노드 제외 노드들)는 최소$\lceil \frac{M}{2} \rceil$, 최대 $M$개의 자식을 가질 수 있다. 최대 $M$개의 자식을 갖는 B 트리를 $M$차 B 트리라고 한다.▼

3. 노드에는 최대 $M-1$개 부터 $\lceil \frac{M}{2} \rceil - 1$개의 데이터가 포함된다.
4. 특정 노드의 데이터(key)가 $K$개라면, 자식 노드의 개수는 $K+1$개여야 한다.
5. 특정 노드의 왼쪽 서브 트리는 특정 노드의 데이터보다 작은 값, 오른쪽 서브 트리는 큰 값으로 구성된다.▼

6. 모든 리프 노드들은 같은 레벨에 있다.
조회
조회는 이진 탐색과 유사하게 진행된다.
찾고 싶은 값을 14라고 해보자.▼
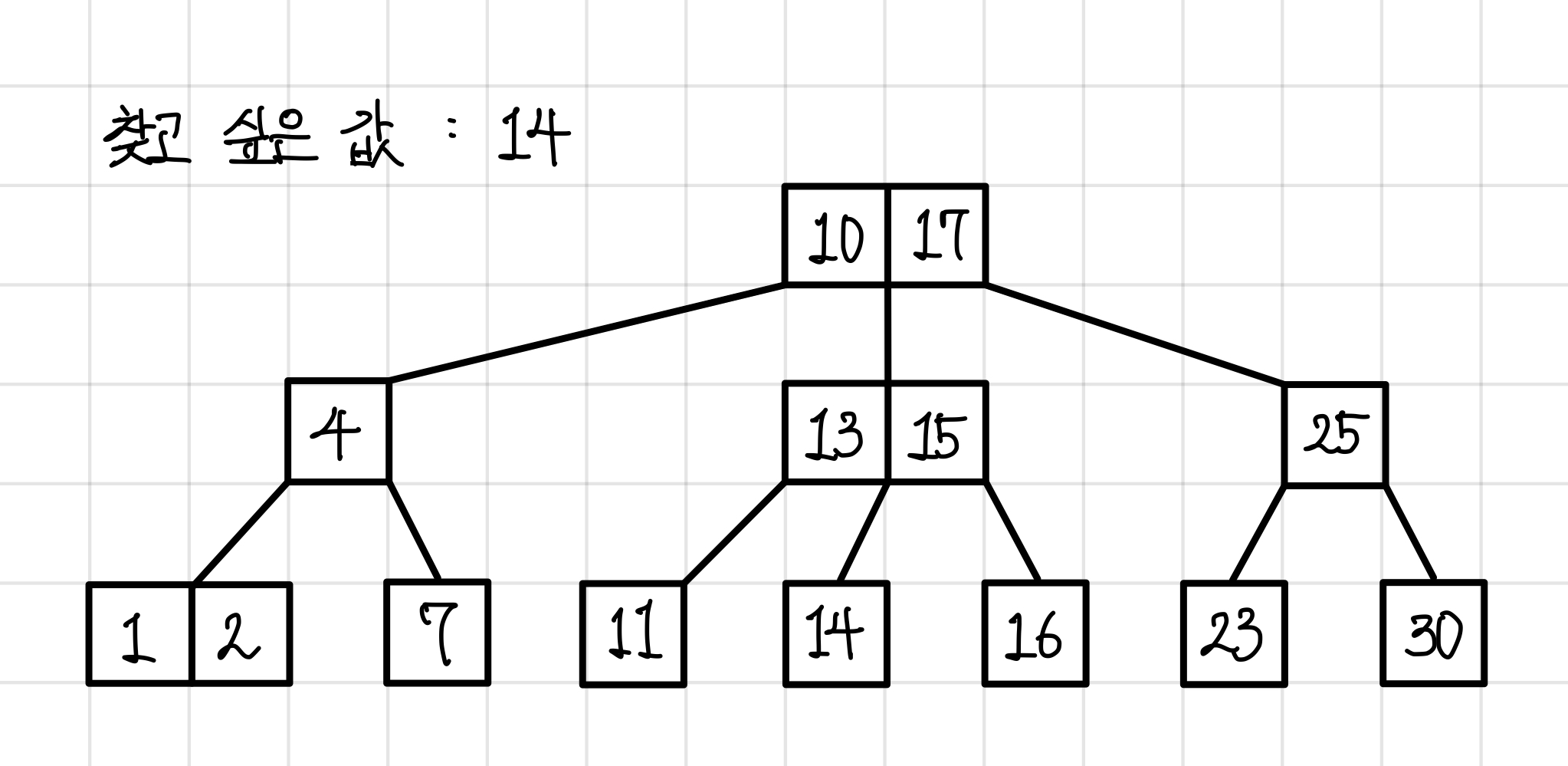
조회는 하향식으로 이루어진다.
루트 노드에서부터 값의 범위를 확인한다.
14는 10과 17 사이의 값이기 때문에 가운데 경로로 내려간다.▼
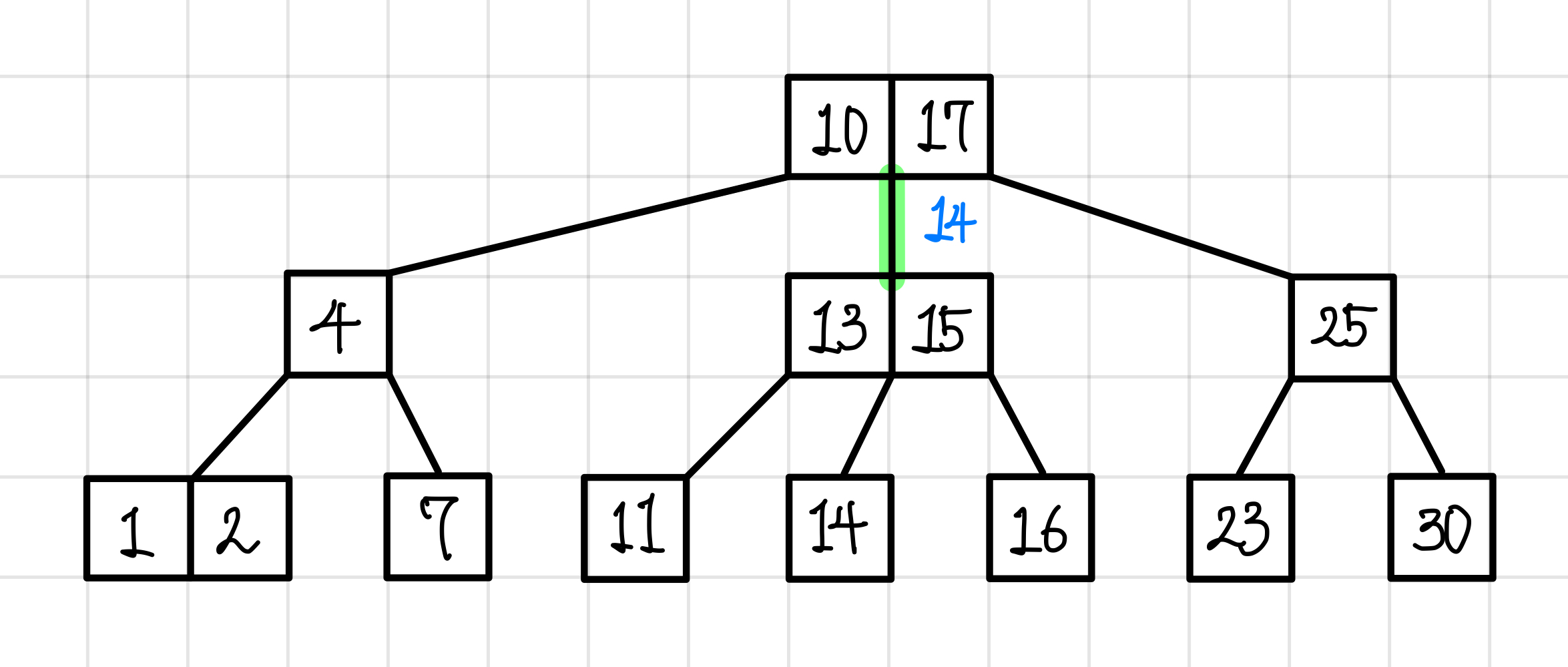
내부 노드로 내려와서도 똑같은 방법으로 탐색한다.
14는 13과 15 사이의 값이므로 이번에도 가운데 경로로 내려간다.▼

가운데 경로로 내려가서 값을 탐색했을 때 14가 있으므로 조회에 성공한다.▼

이진탐색의 기법을 유사하게 따라가기 때문에 값의 범위에 맞지 않는 트리는 모두 무시할 수 있다.
이런 식으로 빠른 속도로 값을 조회할 수 있다.
삽입
B트리가 조회에 준수한 속도를 보인다는 것을 알았다.
그러나 이건 CRUD의 R만 본 것인데, 과연 CREATE(혹은 INSERT)가 빠를까?
B트리의 삽입에는 두 가지 경우가 있다.
구조가 변경되는 경우와 변경되지 않는 경우다.
구조가 변경되지 않는 경우
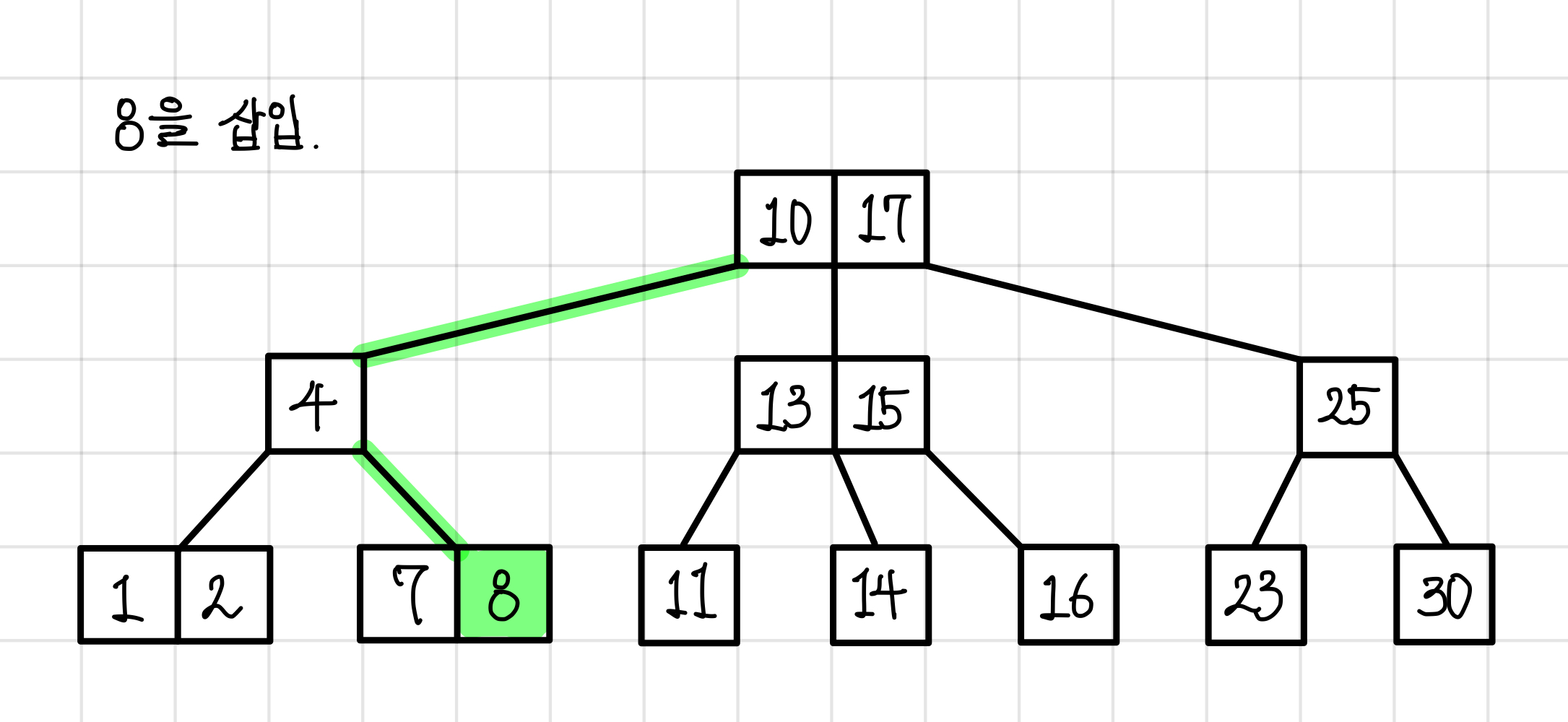
8을 삽입한다고 해보자.
적절하게 조회를 하여 8이 들어갈 자리를 확인하고 8을 넣어본다.
B트리의 규칙에 위배되지 않기에 그대로 삽입이 된다.▼
구조가 변경되는 경우
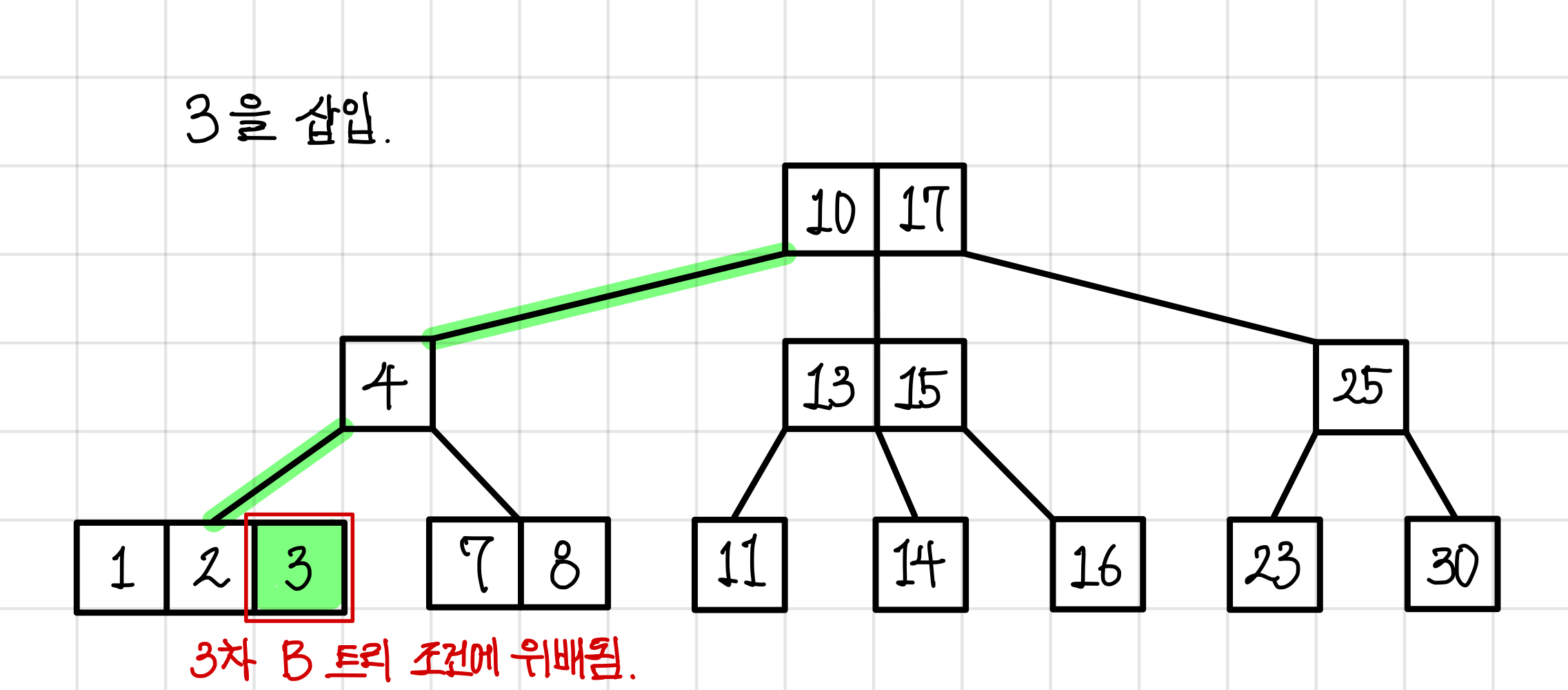
이번에는 3을 추가로 삽입한다고 해보자.
아까와 마찬가지로 3이 들어갈 자리를 조회하고, 그 자리에 3을 넣어본다.
그러나 이번에는 B 트리의 조건에 위배되기 때문에 구조 변경이 필요하다.▼
구조 변경을 위해 3이 들어간 노드의 중간 값을 찾는다.
중간 값은 2로 결정이 되었다.▼

이제 2를 위의 노드로 올려준다.
위의 노드에는 이제 값이 3개가 됐으므로 서브 트리를 3개까지 가질 수 있게 되고, 규칙에 위배되는 내용도 없어진다.▼

제거
이번에는 제거를 보자.
아까의 트리에서 1을 제거한다고 해보자.▼

1을 제거하는 순간 B트리 규칙을 위배하게 된다.
부모 노드에 데이터가 2개 들어가 있기에 자식 노드가 3개여야 하는데 1을 제거함으로써 자식노드가 2개밖에 안되기 때문이다.▼
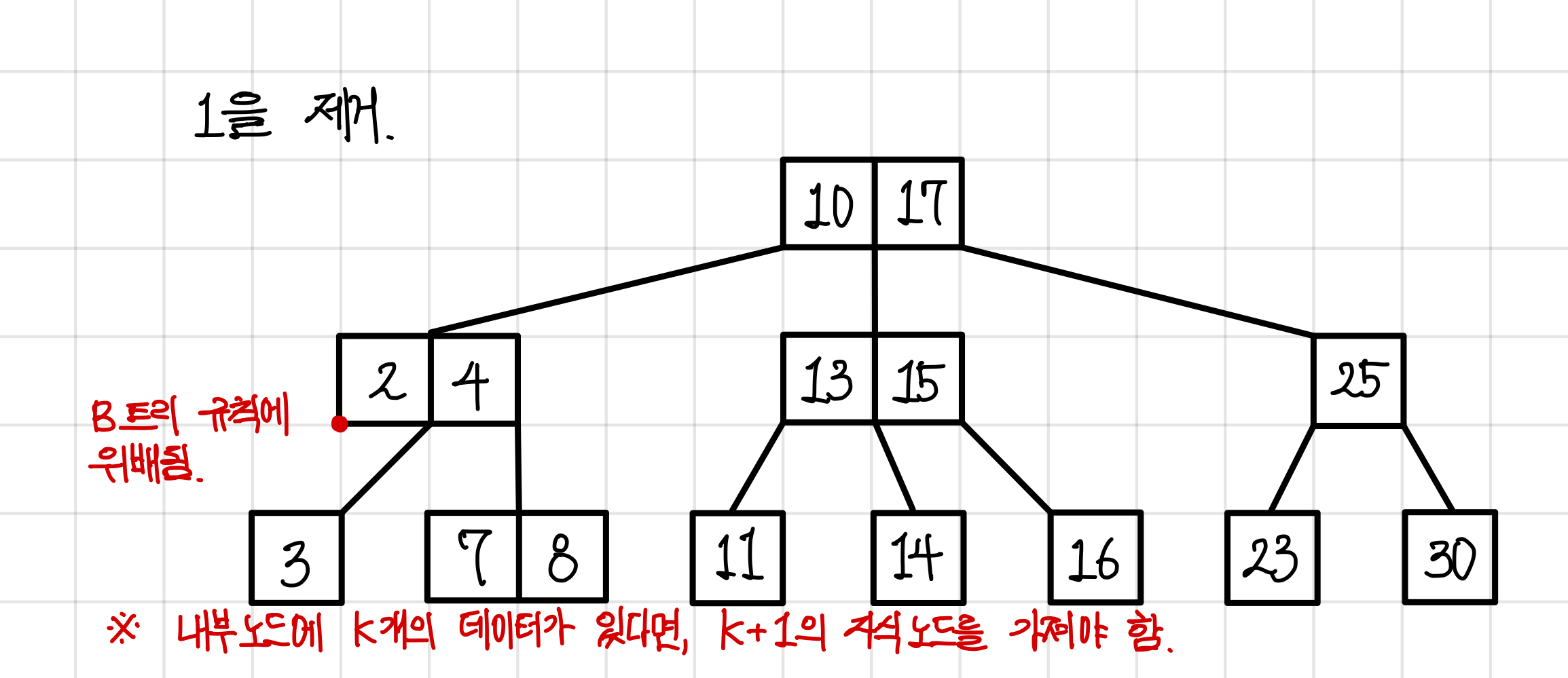
그래서 이번에는 부모 노드의 값을 하나 내림으로써 규칙을 맞춰준다.

한계
B 트리는 꽤나 이상적인 구조를 하고 있다.
조회와 삭제에서 준수한 성능을 보여주지만, 조금 부족한 느낌을 준다.
삽입과 삭제를 할 때 구조 변경이 일어나면서 그로 인한 오버헤드가 발생하기 때문이다.
이를 좀 더 보완한게 B+ 트리다.



