

개론
관계형 모델의 고안자인 에드거 F. 커드가 1970년에 처음으로 정규화의 개념을 도입하였다.
제 1 정규화를 발표한 이후에 이어서 제 2 정규화와 제 3 정규화를 정의하였고, 이후에는 레이먼드 F.보이스와 함께 보이스-코드 정규화(BCNF)를 정의하였다.
4 정규화 이후에는 다른 이론가들에 의해서 정의가 되었다고 한다.
위에가 간단한 정규화에 대한 역사였고, 본론인 정규화의 목적을 이야기하면,
정규화(Normalization)의 기본 목표는 불필요한 중복을 제거하는 것이다.
중복이 언제나 나쁜 것은 아니다.
때로는 설계상 중복이 필요할 때도 있다.
하지만 나쁜 것은 불필요한 중복이다.
이런 불필요한 중복은 데이터 베이스를 모호하게 만들고 각종 오류를 야기한다.
그렇기에 이런 불필요한 중복을 줄이기 위해 정규화라는 것이 등장했고, 굉장히 중요한 개념이다.
하지만 그렇다고 정규화가 언제나 좋은 것은 아니다.
정규화를 통해 테이블이 쪼개지면서 JOIN 연산등이 느려질 수도 있기 때문이다.
그럼에도 정규화는 필수적인 개념이며 꼭 알아야하는 것들이다.
이제부터 제 1 정규형부터 하나씩 보도록 하자.
제 1 정규형 (1NF)
레코드는 atomic 해야 한다.
원자성(atomic)이 보장되어야 한다.
각 Column이 하나의 값(속성)만을 가져야 하며, 하나의 Column은 같은 종류나 타입을 가져야 한다.
즉, 한 Column이 하나의 값만 가져야 한다.
예제
아래의 Table은 원자성을 보장하지 않는다.▼

Smith의 Email에 2개의 Email이 들어가 있기 때문이다.
위의 Table을 제 1 정규형에 맞게 분해하면 아래와 같이 된다.▼

제 2 정규형 (2NF)
1NF를 만족하며, Primary Key에 Partial Functional Dependency가 없어야 한다.
Partial Functional Dependency (부분적 함수 종속)
Functional Dependency
Partial Functional Dependency를 알기 전에 Functional Dependency가 뭔지부터 알아보자.
Attribute 집합 A가 attribute 집합 B의 값을 결정하는 것을 말한다.
예제를 보면서 확인해보자.
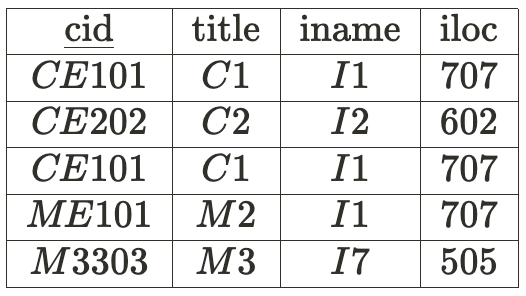
아래의 테이블을 보면 sid가 sname과 addr, major를 결정한다.▼

그리고 cid가 title, iname, iloc을 결정한다.
또, sid와 cid가 grade를 결정한다.
이런 관계를 Functional Dependency라고 말한다.
그렇다면 Partial Functional Dependency는?
Partial Functional Dependency는 앞에 partial, 부분적인이라는 수식어가 붙은 FD이다.
위의 sid가 sname과 addr, major를 결정하긴 했지만 table의 모든 attribute를 결정한게 아니다.
따라서 부분적으로 결정했다고 볼 수 있고 이런 관계를 Partial Functional Dependency라고 부른다.
제 2 정규형에서는 이런 Partial Functional Dependency가 없어야한다고 하는데 이를 없애기 위해서는 테이블 분리가 필요하다.
예제
insert 문제
아래와 같이 attribute들이 있다고 하자.▼
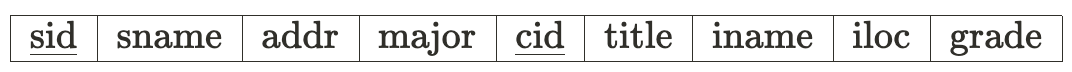
이번에 새로 입학한 학생들이 생겼는데, 수강신청 기간이 아직이라서 학생들이 수업을 등록하지 못했다고 해보자.
이 상황에서 수업 정보는 없기 때문에 cid는 null로 넣어놓아야하지만 primary key 이기 때문에 비울 수 없다.
그리고 primary key가 아니더라도 Column의 값을 null로 해놓는 것은 굉장히 위험한 행동이기에 이 상황 자체가 문제가 된다.
delete 문제
아래와 같이 table이 있다고 해보자.▼

현재 이 상황에서 cid가 CE101, CE202인 수업이 교과목 개설이 안되어 사라졌다.
문제는 우리는 수업만 없애고 싶었는데 CE101, CE202을 지움으로 학생 정보도 같이 지우게 된다.▼

update 문제
이번에는 update를 할 때의 문제를 보자.▼

CE101 수업을 듣는 학생 A가 개명을 해서 Y라는 이름으로 바꿨다고 해보자.▼

그런데 CE202 수업을 듣는 A의 이름은 바뀌지 않게 되면서 비일관성이 발생하게 된다.
문제의 해결
위의 문제들을 해결하는 방법이 바로 Partial FD를 제거하는 것이고, 이는 테이블의 분리를 통해 행해진다.
sid → sname, addr, major 의 관계를 보여주고,
cid → title, iname, iloc 의 관계를 보여주며,
sid, cid → grade 의 관계를 보여주기에 3개의 테이블로 분리하면 해결이 된다.▼



제 3 정규형 (3NF)
2NF를 만족하며, Transitive Functional Dependency가 없어야 한다.
Transitive Functional Dependency
Attribute 집합 A가 attribute 집합 B를 결정하고, attribute 집합 B가 attribute 집합 C를 결정하고, attribute 집합 A가 attribute 집합 C를 결정하는 관계를 말한다.
위의 테이블 예제를 다시 한 번 보자. ▼

cid는 iname을 결정하고, iname은 iloc을 결정한다.
반대로 cid는 iloc을 결정하고, iloc은 iname을 결정한다.▼
$$ cid → iname → iloc $$
$$ OR $$
$$ cid → iloc → iname $$
이렇게 연쇄적으로 값이 결정되는 경우를 Transitive Functional Dependency라고 한다.
예제
위의 예제를 다시 보자.
아래는 제 2 정규화가 완료된 테이블들이다.▼


이 테이블들에서 2번째 테이블에서 Transitive FD가 발견되었기에 이를 분리해줘야한다.
이를 적절히 분리하면 아래와 같이 나눌 수 있다.▼




하지만 이는 iname이 그 자체로 식별가능하다는 전제 하에서 적절하게 분리됐다고 할 수 있다.
iname이 4번째 테이블의 primary key로 적절한가에 대한 것은 또 다른 이야기다.
Q. iname이 primary key로 부적절하면 어떡하죠?
A. 만약 iname이 primary key로 부적절하다면 종본이나 사본을 만들어 관계를 맺어줘야한다.
하지만 이는 제 3 정규화를 하는 작업과는 상관 없는 이야기다.
제 3 정규화 이후의 문제기에 이후의 내용에서 다루겠다.
제 3.5 정규형 (3.5NF, BCNF)
테이블 F에 있는 a→b 형태를 만족하는 모든 FD를 f라고 할 때,
BCNF를 만족하려면 아래의 두 조건 중 하나를 만족해야한다.
1) f는 trivial dependency이다.
2) a는 superkey다.
1) f는 trivial dependency이다.
테이블에 있는 attribute가 모두 prime attribute면 trivial dependency이다.
2) a는 superkey다.
Superkey는 최소성과 상관없이 식별할 수 있는 key이다.
상당히 추상적인 내용이라 이해하기가 어렵다면 역으로 생각하여 조건에 반하는 것을 생각하자.
즉, Super key가 아닌데 prime attribute를 만족하는 애가 있다면 그건 문제다.
예제
아래와 같은 테이블이 있다고 해보자.▼

지금의 관계는 sid와 major가 advisor를 결정한다.
$$ sid, major→ advisor $$
지금의 관계에서는 sid와 major는 super key다.
하지만 반대의 경우를 생각해보면, advisor가 major를 결정한다.
이 경우에 1번 학생이 졸업하여 학생 정보를 지웠다고 하면, 해당 전공을 맡고 있는 advisor도 지워지게 된다.▼

그래서 이런 상황이 발생하지 않게 advisor를 중심으로 테이블을 분리해야한다.▼


이렇게 분리를 하게 되면 학생 정보를 제거해도 전공을 맡은 advisor의 정보가 지워지지 않는다.
제 4 정규형 (4NF)
BCNF여야 하며, candidate key도 아니고 super key도 아닌데 다른 두 column을 결정하면 안된다.
Multi-value Dependency가 둘 이상 있으면 안된다.
Multi-Value Dependency
Super key인 attribute 집합 A의 값 하나가 여러 개의 attribute 집합 B의 값을 결정하는 것을 말한다.
아래의 테이블의 경우, database라는 값은 고라니, 노루, 사슴이라는 instructor 값을 결정하게 된다.▼

예제
아래의 테이블을 보자.
아래의 테이블은 database 담당 교수는 실버셰츠와 라마크리슈난으로 강의를 해야한다는 조건을 토대로 만들어졌다. ▼

$$ course→→instructor\course→→textbook $$
현재 course는 candidate key가 아니다.
그렇다고 super key도 아니다.
허나 course가 instructor와 textbook를 결정하고 있다.
이 상황이 문제가 되는 이유를 알아보자.
위의 테이블에 새로운 레코드를 넣어보자.▼

이렇게 되면 database 담당 교수는 실버셰츠와 라마크리슈난으로 강의를 해야한다는 조건에 부합하지 않게 된다.
추후에 새로운 레코드가 들어오면 괜찮지만, 현재 테이블을 보면 위의 조건을 어긴 것과 같이 나오게 된다.
위의 조건을 만족시키기 위해서는 무조건 아래에 새로운 레코드를 추가해야한다.
그러나 이런 작업은 DB에서 자동으로 해주지 않는다.▼

이를 해결하기 위해서는 아래와 같이 분리를 하면 된다.▼


이렇게 분리를 하면 새로운 레코드를 추가할 때 값의 중복이 줄어든다.
엘크를 추가한 예시다.▼


제 5 정규형 (5NF)
제 4 정규형 이후의 정규형들은 에드거 F.커드에 의해 정의된 개념은 아니다.



