

Verification & Validation
Testing은 Verification과 Validation의 과정이라고도 할 수 있다.
Verification과 Validation의 차이는 앞의 게시물인 Processs Activities에서 잠깐 다뤘었다.
간단하게 둘의 차이점에 대해서 설명을 하자면,
Verification은 개발자 입장에서의 테스트이고, Validation은 유저 입장에서의 테스트이다.
Static and Dynamic Verification
Verification에는 두 가지 종류의 Verification이 존재한다.
하나는 Static, 다른 하나는 그 반대인 Dynamic이다.
Static은 Software Inspections 라고 부르기도 하고, Dynamic은 Testing이라고 바꿔 부르기도 한다.

Inspection(static)의 방식은 코드를 직접 구동시키기 전에 문제점이 있는 지 확인하는 방식이고, 그와는 반대로 Testing(dynamic)의 방식은 테스트 데이터를 직접 넣어서 확인하는 방식이다.
"그러면 Inspection과 Testing 중 하나를 골라서 수행을 하면 되는 것일까?"
아쉽게도 둘 중 하나만으로는 전체를 확인할 수 없다.
Inspection과 Testing은 상호 보완적인 관계이기 때문이다.
Inspection은 코드를 직접 컴파일 하지 않고 문제점들을 잡아내지만, non-functional 요소를 체크할 수 없다는 단점이 있다.
성능도, UI도 확인하지 못하기에 Testing을 통해 부족한 부분들을 보완한다.
Inspections
Inspecton 방식은 이상현상이 일어날 가능성이 있는 코드와 직접적인 문제를 일으키는 버그를 찾기 위해 코드 확인하는 방식이다.
코드 실행을 하지 않아도 되기에 구현(implementation)전에 확인이 가능하다는 장점이 있다.
프로그램 에러를 찾기에 효과적인 방법이라고 할 수 있다.
Inspection Success
Inspection 방식은 여러 버그를 찾기에 효과적이다.
Testing은 한 번에 한 버그만 발견된다.
요즘엔 컴파일러가 어디가 문제라고 다 알려줘서 무수한 에러의 요청을 받긴 하지만, 그 에러들이 한 곳에서 일어났는지, 아니면 각자 다른 부분에서 일어났는지 직접 확인해야한다.
결국에는 가장 윗부분의 에러부터 확인하고 고치는 과정을 거쳐야하기 때문에 Testing으로는 한 번에 한 버그만 발견할 수 있다.
하지만 Inspection 방식은 코드를 전체적으로 확인하기 때문에 문제가 생긴 코드가 연쇄적으로 일으킬 다른 문제들에 대해서도 확인할 수 있다.
"그렇다면 무조건 Inspection을 해야겠네요!"
꼭 그런 것만은 아니다.
Inspection을 초보 개발자에게 시킨다고 다 잘하는 것은 아니기 때문이다.
기본적으로 프로그래밍 언어에 대한 지식이 많은 사람들이 Inspection에 유리하다.
언어에 대한 숙련도가 없는 상황에서 Inspection을 시켜봤자 문제점을 다 찾기엔 역부족이다.
"그러면 코딩 고수들만 할 수 있는건가요?"
하지만 팀으로 진행할 때는 개인의 능력에 전부 기대지는 않는다.
팀으로 진행하게 되면 개인의 역량이 부족하더라도 문제 상황 해결을 할 수 있기 때문이다.
어느정도의 가이드라인을 따르면 팀 단위로 Inspection을 진행할 수 있다.
Program inspection
Inspection은 문서들을 확인하는 formal한 접근 방식이다.
앞에서도 말했지만 inspection의 주 목적은 결점(defect)를 찾는 것이다.
"결점을 찾았다면 무엇을 할까?"
"결점을 찾았다면 당연히 고쳐야죠?"
당연히 이런 흐름으로 진행이 되겠지만, 결점을 찾았다고 바로 고치지 않는다.
왜냐면 결점을 찾는 주체는 해당 결점이 있는 코드를 짠 개발자가 아니라, 결점을 찾는 다른 팀이기 때문이다. (Inspection 팀이라고 부르겠다.)
Inspection 팀이 결점을 찾았다면, 그 결점에 대한 정보를 개발자에게 보내준다.
그리고 개발자들은 그 결점을 고치는 계획을 세워 프로그램을 고치는 작업에 들어가게 된다.
"그럼 Inspection 팀은 어떤 것을 결점이라고 칭하고 보내는 것일까?"
Inspection 팀은 논리 문제(logical error)와, anomalies를 결점으로 판단한다.
Inspection pre-conditions
Inspection 팀은 Inspection을 시작하기 전에 다음의 것들을 준비되었는지 확인한다.
Precise specification
"코드를 돌려보지도 않는데 어떻게 잘못되었는지 판단하죠?"
Inspection의 기준이 되는건 코드를 컴파일해서 나온 결과물이 아니라, 가장 먼저 작성했던 Specification이다.
초기에 기획했던 내용들을 토대로 문제가 생기는지 안생기는지를 확인하기 때문에 정확한 Specification을 필요로 한다.
Syntactically correct code
문법적으로 정확한 코드는 Inspection 팀에서 찾을 내용이 아니다.
개발자가 문법을 정확히 해야할 부분이다.
Error checklist
코드가 만족해야 할 요소들을 정리해놓은 리스트이다.
이에 대한 내용은 조금 뒤에 더 자세하게 볼 것이다.
Inspection을 할 때 마음가짐
Inspection을 할 때는 문제 검출을 위한 Inspection이 되면 안된다.
반증을 위한 반증과 같은 느낌으로 Inspection을 진행해서는 안된다는 것이다.
또한 아는 사람의 기분을 좋게 해주기 위해서 어물쩡 넘어가는 것도 좋지 않다.
순간적인 사회생활은 좋아질 지 몰라도, 이로 인해 여러 문제점이 발생하면 나중의 사회생활은 오히려 안좋아질 수도 있다.
Error checklist
Error checklist는 이름 그대로 에러들을 모아놓은 체크리스트로, 일반적으로 많이 발생할 수 있는 에러를 모아다가 리스트로 만든 것이다.
실제 Inspcetion을 진행할 때 이 체크리스트 대로 체계적으로 확인해본다.
에러 체크리스트는 프로그램 언어에 따라 다르다.
C, C++, Python 등등에 따라 에러 체크리스트의 내용이 다른데 그걸 쉽게 보여주는 이유가 Type checking이다.

Type Checking이 약한 언어는 개발자의 의도인지 아닌지를 확인해야하기에 체크할 게 더 많아진다.
그 외에도 무한 루프가 될 가능성이 있느냐, 배열 범위 초과 등등을 확인한다.
Data Faults
- 프로그램 변수가 실제 사용되기 전에 초기화가 되었는지?
값을 할당하지 않았다면 쓰레기 값이 들어가기에 오류가 날 것이다. - 배열 인덱스가 배열 크기 - 1 범위 안에 있는지?
배열 범위를 넘어가서 접근하면 메모리 접근 문제가 발생한다. - 문자열 크기를 제대로 정했는지?
C에서는 Null을 구분자(delimiter)로 사용하기에 실제 문자 개수보다 하나 더 많이 설정해줘야한다.
단어 “gorani”를 저장할 때 character가 몇 개나 필요할까?
답은 Null까지 7개이다. - 오버플로우가 일어나지는 않았는지?
각 타입의 범위 내의 값을 할당해야한다.
Control Faults
- 조건 식이 제대로 되었는지 확인했는가?
조건 식이 반대로 되어있거나, 맞지 않거나 할 수 있으니 반드시 확인해야 한다. - 반복문에 종료 조건이 있는지 확인했는가?
무한루프가 될 가능성이 있는지 확인해야한다.
while 루프나 for문에서 조건식이 잘못되면도 발생하니 잘 확인해야한다. - 중괄호를 제대로 설정했는가?
- switch문에서 break가 제대로 들어갔는가?
Input/Output Faults
- input된 변수가 사용었는지?
- output 하기 전에, output 변수에 값이 할당 되었는지?
- 예상치 못한 인풋에 대해서 어떻게 할 것인지?
Interface Faults
- 매개변수의 수와 순서가 잘 맞는지?
“이런걸 틀리는 사람이 있나요? 요즘엔 IDE에서 다 알려주는데요?”
지금은 매개변수가 많아봤자 2개에서 3개인데, 시스템이 커지면 매개변수의 수도 많아지기에 순서를 틀릴 수 있다.
매개변수가 String 타입으로 4개가 연속으로 들어가게 되면 충분히 헷갈릴 수 있다. - 정의한 매개변수의 타입과 실제로 들어가는 타입이 맞는지?
- 만약 구성 요소가 공유 메모리에 접근한다면, 그들은 동일한 공유 메모리 구조 모델을 가지고 있는지?
공유 메모리는 여러 개의 구성 요소 또는 프로세스가 데이터를 공유하는 메모리 영역을 의미한다.
따라서, 구성 요소들이 공유 메모리를 효율적으로 사용하기 위해 동일한 구조 모델을 사용해야 한다는 것을 의미한다.
이는 데이터의 일관성과 정확성을 유지하며, 서로 다른 구성 요소들 간의 충돌이나 오류를 방지하기 위해 중요한 요소이다.
Storage management Faults
- 연결된 구조의 한 부분이 바뀌었을때, 다른 부분의 연결들도 재할당이 되었는지?
- 동적 메모리를 사용할 때 동적 메모리가 제대로 할당이 되었는지?
최근 언어들은 garbage collector가 있기에 이런 부분들에 대해 크게 고민하지 않아도 되지만, C와 C++와 같은 언어들은 이에 대해 민감하게 반응할 필요가 있다. - 더 이상 필요가 없는 메모리를 해제했는지?
메모리를 해제하지 않으면 메모리를 사용하지 않는데도 점유하게 되어 성능 손실이 발생하게 된다.
이를 memory leak이라고 하며, 만약에 반복문에서 memory leak이 발생하면 치명적인 문제가 발생할 수 도 있다.
Exception management Faults
- 마지막으로 에러 다 확인했는지?
위의 체크리스트들은 얼핏보면 당연한 것들 같지만, 이런 당연한 것들이 확인이 안될 때가 많다.
컴파일이 한 번에 잘 된 적이 많은지 생각해보면, 아마 대부분 그렇지 않다고 생각할 것이다.
그런 경험을 생각해보면 위의 체크리스트의 항목들이 중요한 것이란걸 느낄 수 있다.
Inspection procedure & rate
Inspection은 아래의 절차대로 수행되곤 한다. ▼
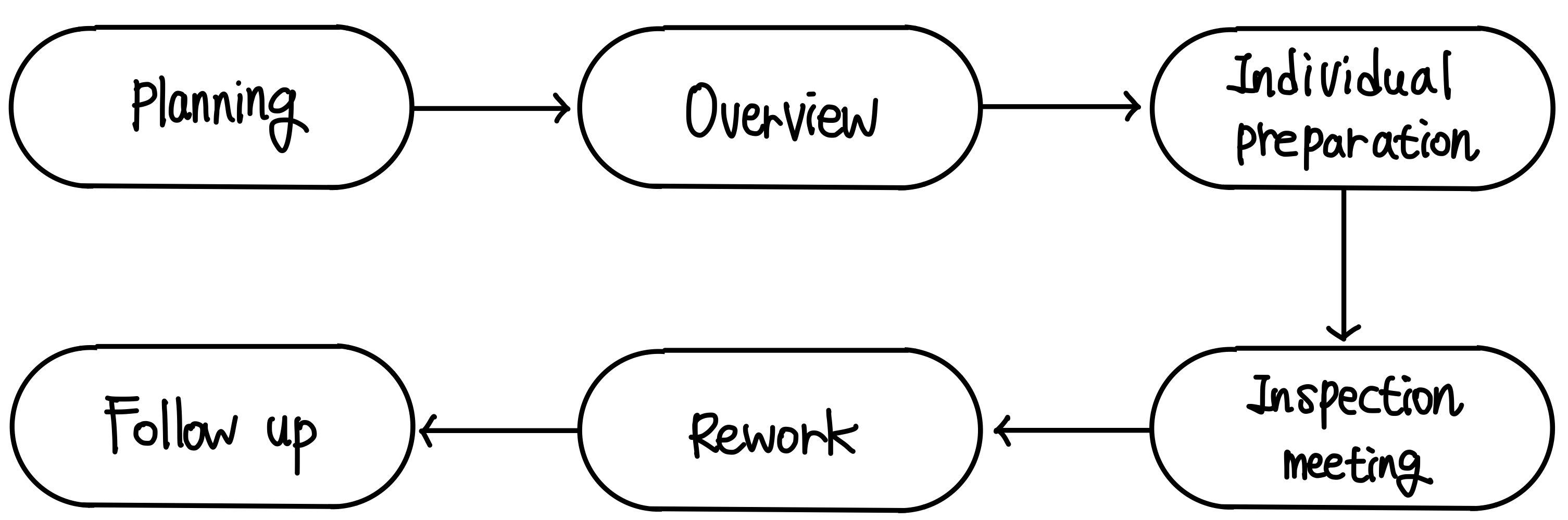
그리고 Overview, Individual Preparation, Inspection meeting에서 코드를 확인하는 시간을 가진다.
일반적으로 시간당 아래의 수치만큼 코드를 검사하게 된다.
- Overview : 500 statements/hour
- Individual Preparation : 125 statements/hour
- Inspection Meeting : 90-125 statements/hour
개인이 준비할 때(individual preparation) 1시간 동안 125줄을 보라고 하면 1시간이 굉장히 길게 느껴질 것이다.
그런데 Inspection Meeting 때는 그보다 코드 한 줄에 더 많은 시간을 사용하여 확인하게 된다.
이런 측면에서 Inspection은 굉장히 중요하고, 자원이 많이 들어가는 절차임을 알 수 있다.
Automated Static Analysis
Inspection이 중요한 것은 알겠지만, 시간이 너무 오래걸린다는 점이 걸리게 된다.
그래서 시간을 줄이기 위해 기계, 툴에게 맡겨 자동화 시킨다.
그러나 어디까지나 툴은 사람을 지원해주는 용도이고, 결정은 사람이 해야한다.
툴은 모든 것을 대신해줄 수 있지 않다.
허나 툴을 사용하면 시간을 획기적으로 줄일 수 있다.
아래는 LINT 툴을 통해 C코드를 분석한 것이다. ▼

Lint 도구는 개발자가 실수로 인한 버그를 미리 발견하고 수정할 수 있도록 도와주는 중요한 도구이다.
코드의 가독성, 유지보수성, 신뢰성을 향상시키는 데에 도움을 주며, 팀 전체에서 일관된 코딩 스타일을 유지할 수 있도록 지원한다.
이런 툴들을 통해 Inspection을 수행하는 시간을 줄일 수 있다.
Testing
Testing은 프로그램이 동작을 제대로 수행하는지 확인하는 것이다.
동작을 제대로 하지 않는다면 이를 defect, bug로 취급한다.
결국에는 직접 동작을 시켜서 에러가 있다는걸 찾는 것이다.
굉장히 간단하고 직관적인 방식이다.
하지만 Testing에는 한계가 있다.
Testing에는 Exhaustive Testing이라는 말이 있는데, 이는 모든 것을 다 커버하는 테스팅이라는 말이다.
그런데 단어가 조금 눈에 띄지 않는가? Exhuastive라니?
모든 걸 다 커버하는 테스트의 이름에 소모적인이라는 단어가 붙은 이유는, 모든 것을 다 테스트하는 것이 굉장히 자원을 소모하는 일이기 때문이다.
if-else문이 5개가 중첩이 되어있다고 해보자.
그러면 발생할 수 있는 조건은 2^5으로 32가지나 있다.
이미 이정도만 해도 32가지가 나오는데, 변수에 대한 조건, 반복문에 대한 조건, 클래스에 대한 조건들이 모두 중첩이 되면 테스트해야할 조건들이 너무나도 많아지게 된다.
모든 것을 테스트한다는 것은 굉장히 소모적이라는 것이다.
그렇기에 Inspection을 통해 테스트할 것들을 걸러내고 Testing을 한다.
"그렇다면 inspection으로 전부 걸러버리면 되는거 아닌가요?"
초반부에 잠깐 언급했지만, 둘은 상호 보완적이다.
Inspection은 non-functional한 요소에 대해서는 확인할 수 없다.
단순히 코드를 들여다 보는것으로 어느정도의 퍼포먼스를 보여줄 지, 어떤 디자인이 나올 지 예측하기는 어렵다.
그렇기에 이런 Inspection으로 확인이 되지 않는 것들을 Testing을 통해 확인한다.
Testing의 종류
Validation Testing
초반부에서 Verification과 Validation의 차이점에서 언급했었다.
Inspection이 개발자 입장에서의 Verification을 한다면, Testing은 유저 입장에서의 Validation을 해야한다.
‘잘 만들었는가?’에 대해 생각하는 것이 아니라 ‘요구 사항대로 만들었는가?’ 에 대해 생각하고 이를 테스트 해보는 것이다. ▼
Defect Testing
Defect Testing은 이름 그대로 결점을 찾는 Testing이다.
Defect testing을 통해 버그를 최대한 많이 찾아야한다.
Testing & Debugging
"Testing과 Debugging은 어떤 차이가 있을까?"
둘 다 버그를 찾는 행위가 아닌가 하는 생각이 들 수 있는데, 둘은 엄연히 다른 행위다.
프로그램의 문제점을 없애기 위함이라는 목적은 같지만, 하는 행동에서 차이가 난다.
Testing은 문제점을 찾는데 집중한다면, Debugging은 문제점을 없애는데에 집중한다.
Testing과 Debugging은 보통 다른 팀에서 행해진다.
테스트하는 팀은 테스트만 하고, 개발 팀에서 버그를 주로 고친다.
"Testing과 Debugging을 통해 버그를 없애는데 그렇다면 Debugging을 할 때 가장 중요한 요소는 무엇일까?"
이는 재현이 안되는지 확인하는 것이다.
재현이 안되면 이 버그가 어디서 왜 생겼는지 확인할 수 없다.
어디서 발생했는지만 알아도 고칠 수 있는데, 재현이 되지 않으면 문제가 되는 부분을 특정할 수 없기 때문에 어떻게 이런 버그가 발생했는지 알아야 한다. ▼

그러면 Debugging을 하면 다 해결이 된 것일까?
아쉽게도 아니다. 다시 inspection과 Testing을 해야한다.
바뀐 부분에서 문제가 생기는 일이 매우 빈번하게 일어나기 때문에 바꾼 부분에서 문제가 생기지 않게 잘 조절 해야한다.
변경점에서 문제가 얼마나 생겼으면, 이를 Regression testing이라는 이름으로 별도의 이름도 지어놓았다.
Testing Process
Testing 절차에는 크게 2가지가 있다.
하나는 Component Testing으로 한 개발자가 혼자 개발할 수 있는 단위 만큼을 테스트하는 것으로 생각하면 된다.
클래스 단위의 Teseting이라고 생각하면 된다.
한 개발자가 혼자 개발할 수 있는 단위 만큼의 Teseting이기에 이는 개발자가 맡아서 테스트를 진행한다.
다른 하나는 System Testing이다.
개발자들이 Component단위로 개발을 진행했다면, 언젠가는 이를 합쳐야한다.
이 요소들을 붙이는 과정에서 생기는 문제점을 확인하는 것이 System Testing이다.
이는 개발자 각자가 하는 것이 아니라 독립적인 Testing 팀에서 진행한다.
시스템 테스팅은 크게 Integration testing과 Release testing의 두 가지 단계를 가진다.
System Testing : Integration Testing
Integration Testing은 Component들 간의 상호작용에 대해 Testing을 한다.
상호작용에서 일어날 수 있는 문제들에 대해 Testing을 한다.
Component가 30개가 있다고 하고, 한 번에 integration한다고 생각해보자.
분명 어딘가에서 문제가 생길 것인데, 문제는 어디서 발생했는지를 찾기가 어렵다.
30개를 합쳤으니 말이다.
그래서 Incremental integration testing을 한다.
하나씩 Component들을 추가하면서 진행하는 Testing이다. ▼

점진적으로 추가하며 Testing을 하게 되면 error localization이 쉬워진다.
처음에는 Component A와 B를 넣고 테스트 케이스 T1, T2, T3를 수행한다.
그다음에 C를 넣고 테스트 케이스 T4를 추가한다.
C와 테스트 케이스 T4가 추가되었다고 이 둘에 대해서만 Testing을 수행하면 안된다.
이전에 했던 테스트 케이스들까지 모두 수행해야한다.
그러면 첫번째 단계에서는 3개의 테스트 케이스에 대해 Testing을 수행하고, 두번째 단계에서는 4개의 테스트 케이스에 대해, 세번째 단계에서는 두번째 단계에서 한 테스트 케이스 + alpha 를 수행해야한다.
이렇게 단계적으로 진행하다가 문제가 발생하면, 어떤 Component들의 어느 부분에서 문제가 발생했는지 error localization이 쉬워진다.
앞에서 조금 어렵게 이야기를 한 것 같은데, 결국엔 Component사이의 인터페이스를 테스팅 하는 것이다.
전에 Class Design에서 정의했던 인터페이스를 테스팅한다고 볼 수 있다.
System Testing : Release Testing
Integration Testing과 다른 Testing들이 다 끝나면 Release Testing을 수행한다.
Release Testing은 실제 고객에게 배포되기 전에 Testing해보는 것을 말한다.
즉, 실제 사용자가 사용하는거 처럼 Testing 해보는 것이다.
이런 Testing을 블랙 박스(Black Box) Testing이라고 한다.
블랙 박스는 안이 안보이고 Input과 Output만 보인다.
안이 안보인다는 의미는 안을 들여다볼 필요가 없다는 의미와도 같기에, 실제 내부 구조에 대해 알 필요 없이 Input과 Output만 알면 되는 것이다.
애초에 테스터가 시스템 구현에 대한 지식을 알 필요가 없다.
전 세계 사람이 개발자인것도 아니고, 일반 사용자들이 개발 지식을 알고 있을 필요도 없기 때문이다.
테스터는 기능이 잘 돌아가는지만 확인하면 된다. ▼

배포 전에 하는 테스트이기에 개발회사에서 마지막으로 하는 테스트인 알파 테스트라고도 부른다.
"그런데 일반 사용자는 프로그램에 대해 아는게 없으니,
개발회사에서 제공하는 테스트 케이스나 테스트 리스트에 의존해야하는데
이 테스트 케이스/리스트는 언제 만들까?"
"개발이 다 끝난 뒤에 만들수 있는거 같은데 배포 시기가 늦어지지 않을까?"
걱정과는 다르게 Release Testing의 테스트 케이스는 Specification이 끝났을 때 만들 수 있다.
기능만 정해지면 무엇을 확인할 지는 다 정해지기 때문이다.
프로그램이 잘 만들어졌는지 아닌지는 테스트 결과를 보고 판단한다.
그렇기에 블랙 박스 테스트의 품질이 좋아야 프로그램의 평가가 제대로 가능해지기에, 테스트 케이스를 잘 만들어야한다.
"그러면 잘 만들어진 테스트 케이스란 무엇일까?"
프로그램을 단순히 헐뜯기 위한 테스트 케이스와는 거리가 멀고, 그렇다고 모든 것을 봐주는 테스트 케이스와도 거리가 멀은 중간의 테스트 케이스가 좋다.
항상 중간이 가장 어렵기 때문에, 한 마디로 정의하자면 에러가 잘 나올거 같은 테스트 케이스가 좋은 테스트 케이스라고 할 수 있다.

고장날 거 같다고 오류가 안날거 같은 테스트 케이스만 넣게 되면 오류 검출이 되지 않는다.
그런 테스트 케이스를 넣을 바엔 최대한 이렇게 넣으면 고장나겠지 싶은 것을 넣는게 더 좋다.
Partition testing
앞에서도 이야기 했지만, Exhaustive Testing은 현실적으로 불가능하다.
너무나도 많은 변수들과 조건들이 존재하기 때문이다.
그래서 최대한 적은 자원으로 실제 코드의 대부분을 커버할 수 있게 Testing을 수행한다.
Equivalence Partitioning Testing
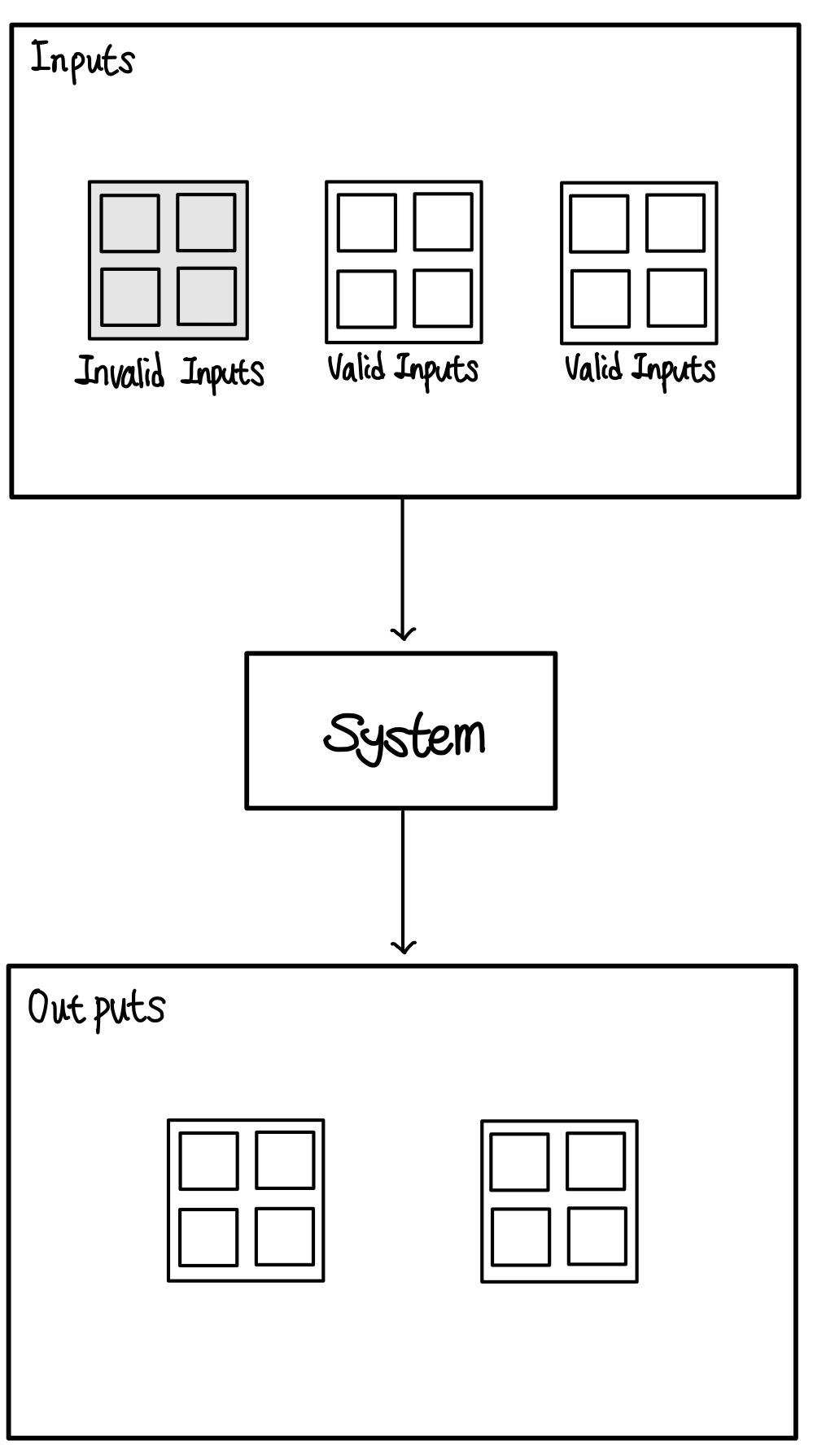
Equivalence Partitioning Testing은 Partition Testing의 전략 중 하나로, 입력 데이터를 대표적인 그룹 또는 등가 파티션으로 분할하여 효율적으로 테스트 케이스를 식별하는 방법이다.
각 파티션은 동일한 특성을 갖는 입력 값의 집합으로 구성된다.
등가 분할 테스팅은 입력 데이터의 중복을 줄이고 테스트 커버리지를 극대화하여 효율적인 테스트를 수행하는 데 도움을 준다.
Equivalence Partitioning Testing은 유사한 입력값들이 테스트 하고자 하는 시스템을 거치면 유사한 답변이 나온다는 것을 가정하고 하는 테스트이다.
특정 분할에 속한 하나의 값은 그 분할 내에 있는 모든 값으로 대표하여 Testing을 진행한다.
일반적으로 경계값 분석기법(boundary value analysis)과 함께 테스트 케이스 도출하는데 사용한다. ▼
경계값 분석기법(boundary value analysis)은 소프트웨어 테스트의 전략 중 하나로, 입력 변수의 경계값을 중심으로 테스트 케이스를 식별하는 방법이다.
이 방법은 주로 입력 변수의 범위에서 발생할 수 있는 오류를 식별하고, 이러한 경계 조건에 대한 효과적인 테스트를 수행하기 위해 사용된다.
일반적으로 시스템들은 입력 변수의 경계값에서 오류가 발생할 가능성이 크기 때문에 이런 경계값을 테스트를 진행하여 오류를 커버한다.
경계값 분석기법은 아래와 같은 순서로 진행이 된다.
- 입력 변수 식별
테스트하려는 소프트웨어 시스템의 입력 변수를 식별한다.
입력 변수는 시스템의 동작을 결정하는 값 또는 매개 변수다. - 경계값 식별
각 입력 변수의 최소값, 최대값, 그리고 그 사이의 중간값을 식별한다.
이들 값은 입력 변수의 경계값이다. - 경계값 기반 테스트 케이스 선택
각 입력 변수의 경계값을 중심으로 테스트 케이스를 선택한다.
이는 최소값, 최대값, 그리고 중간값을 포함하여 선택할 수 있다.
일반적으로 경계값은 오류가 발생할 가능성이 높은 지점을 나타내므로, 이를 중심으로 테스트를 진행하는 것이 중요하다. - 테스트 실행 및 결과 분석
선택된 경계값 테스트 케이스를 실행하고 결과를 분석한다.
경계값에서 발생할 수 있는 오류나 예외 상황을 확인하고, 시스템의 동작을 검증한다.
만약에 입력 값의 개수에 대해서 테스트 한다면, 아래와 같이 경계값을 나누어 테스트 해 볼 수 있다.
입력 값의 전체 범위가 1부터 15라고 하면, 1개부터 15개 전부 테스트하는 것이 아닌 특정 경계값 위주로 테스트한다. ▼

개수 뿐만 아니라 값의 범위도 마찬가지로 수행할 수 있다. ▼

Search Routine Specification
Search Routine Specification은 테스트에서 사용되는 검색 루틴의 동작과 예상되는 결과를 설명하는 문서 또는 명세서이다.
이 명세서는 검색 루틴이 어떻게 동작해야 하는지에 대한 명확한 기준을 제공하여 개발자 및 테스터가 해당 검색 루틴을 효과적으로 테스트할 수 있도록 도와준다.
Procedure
Procedure은 Search Routine의 테스트 절차를 설명한다.
Search Routine의 구체적인 단계와 순서, 그리고 어떤 요소들을 필요로 하는지 정의한다.
테스트 환경, 입력 데이터, Search Routine의 수행 단계, 그리고 예상되는 결과들에 대해 기술한다.
Pre-condition
사전 조건(Pre-condition)은 검색 루틴이 실행되기 전에 충족되어야 하는 조건이다.
이 조건들은 검색 루틴이 올바르게 동작하기 위해 필요한 초기 상태를 정의한다.
Pre-condition은 일반적으로 검색 루틴의 입력 데이터나 환경에 대한 제약 조건입니다. 예를 들어, Pre-condition은 다음과 같을 수 있다.
- 입력 데이터는 정렬된 상태여야 한다.
- 입력 데이터는 유효한 형식이어야 한다.
- 검색 대상이 존재해야 한다.
Post-condition
사후 조건(Post-condition)은 검색 루틴이 실행된 후에 만족되어야 하는 조건이다.
이 조건들은 검색 루틴의 실행 결과나 상태에 대한 기대값을 정의한다.
Post-condition은 일반적으로 검색 결과, 출력 데이터의 상태, 루틴의 부작용 등을 나타낸다.
예를 들어, Post-condition은 다음과 같을 수 있다.
- 검색 결과는 정확한 위치를 반환해야 한다.
- 출력 데이터는 원본 데이터를 수정하지 않아야 한다.
- 루틴은 일정 시간 내에 실행을 완료해야 한다.
Or
Search Routine Specification에서 Or 항목은 특정 동작이 발생하지 않거나, 예상 결과가 나타나지 않는 상황을 설명하는 데 사용된다.
그러나 그것과 별개로도 여러가지 조건을 합쳐서 사용하는데에도 사용이 된다.
이는 검색 루틴이 주어진 조건을 충족시키지 못한 경우로, 테스트 케이스를 설계하고 검증할 때 이러한 상황을 확인하기 위해 Or 항목을 활용할 수 있다.
Search Routine Input Partition
Search Routine의 Input Partition은 입력 데이터를 어떤 기준으로 나눌 지를 정의한다.
그 기준으로는 아래의 것들이 있다.
- 전제 조건을 충족하는 입력
검색 루틴이 요구하는 사전 조건을 충족하는 입력이다.
즉, 검색 시스템이 정상적으로 동작하기 위해 필요한 입력 데이터이다.
이러한 입력은 검색 시스템이 올바른 결과를 생성할 수 있도록 보장한다. - 전제 조건을 충족하지 않는 입력
검색 루틴이 요구하는 사전 조건을 충족하지 않는 입력이다.
이는 잘못된 형식이나 유효하지 않은 데이터로 구성된 입력을 의미한다.
이러한 입력은 검색 시스템이 오류를 처리하고 예외 상황에 대응할 수 있도록 테스트하는 데 사용될 수 있다. - 배열의 키 요소가 포함된 입력
검색 루틴이 특정 배열에서 키 요소를 검색하는 경우, 해당 키 요소가 배열의 구성원인 입력이다.
이러한 입력은 특정 요소를 포함한 검색을 테스트하고 해당 요소가 올바르게 검색되는지 확인하는 데 사용될 수 있다. - 배열의 키 요소가 포함되지 않은 입력
검색 루틴이 특정 배열에서 키 요소를 검색하지만 해당 요소가 배열의 구성원이 아닌 경우, 해당 요소가 없는 검색을 테스트하는 입력이다.
이를 통해 검색 시스템이 키 요소가 존재하지 않을 때 적절하게 처리하고 예외 상황에 대응할 수 있는지 확인할 수 있다.
예제
| Number # | Sequence | Element |
| 1 | Sing Value | In Sequence |
| 2 | Sing Value | Not in Sequence |
| 3 | More than 1 Value | First Element in Sequence |
| 4 | More than 1 Value | Last Element in Sequence |
| 5 | More than 1 Value | Middle Element in Sequence |
| 6 | More than 1 Value | Not in Sequence |
| Number # | Input Sequence (T) | Key(Key) | Output(Found, L) |
| 1 | 17 | 17 | true, 1 |
| 2 | 17 | 0 | false, ?? |
| 3 | 17, 29, 21, 23 | 17 | true, 1 |
| 4 | 41, 18, 9, 31, 30, 16, 45 | 45 | true, 7 |
| 5 | 17, 18, 21, 23, 29, 41, 38 | 23 | true, 4 |
| 6 | 21, 23, 29, 33, 38 | 25 | true, ?? |
- 입력 시퀀스에 단일 값 17이 포함되어 있으며, 17을 찾았으므로 Found 값은 true이다.
17은 첫 번째 요소이므로 L 값은 1이다. - 입력 시퀀스에는 17이 포함되어 있지만, 키로 주어진 값은 0이므로 0을 찾을 수 없다.
Found 값은 false이며, L 값은 정의되지 않는다(물음표로 표시). - 입력 시퀀스에 다수의 값이 포함되어 있고, 키로 주어진 17을 찾을 수 있다.
Found 값은 true이며, 17은 첫 번째 요소이므로 L 값은 1이다. - 입력 시퀀스에 다수의 값이 포함되어 있고, 키로 주어진 45를 찾을 수 있다.
Found 값은 true이며, 45은 일곱 번째 요소이므로 L 값은 7이다. - 입력 시퀀스에 다수의 값이 포함되어 있고, 키로 주어진 23을 찾을 수 있다.
Found 값은 true이며, 23은 다섯 번째 요소이므로 L 값은 4이다. - 입력 시퀀스에 다수의 값이 포함되어 있지만, 키로 주어진 25를 찾을 수 없다.
Found 값은 false이며, L 값은 정의되지 않는다(물음표로 표시).
'CS > 소프트웨어 공학' 카테고리의 다른 글
| 20. Design Patterns (0) | 2024.02.04 |
|---|---|
| 19. Software Architecture (0) | 2024.02.04 |
| 18. Refining The Requirements Model (0) | 2024.02.04 |
| 17. State Machine (0) | 2024.02.03 |
| 16. Designing Boundary Classes (작성중) (0) | 2024.02.03 |



