

Detailed Design
앞에서 그린 Analysis 다이어그램만으로는 코드를 만들 수 없다.
그래서 아래의 것들이 있어야 코드로 표현할 수 있다.
- Types of attributes
- Operation signatures
- Assigning responsibilities as operations
- Additional classes to handle user interface
함수도 리턴 타입과 매개변수 타입을 정의해야한다.
이런 모든 것을 정하는게 Detailed Design이라고 한다.
Class Specification : Atrributes
클래스의 Attribute를 표현할 때는 아래의 문법으로 표현한다. ▼
name ‘:’ type-expression ‘=’ initial-value ‘{’property-string‘}’이름과 타입은 무조건 있어야 하지만, 뒤의 요소들은 꼭 있을 필요는 없다.
필요에 따라 정의하면 된다. ▼

슬래시 ( / ) : Derived Attribute
그런데 variable3 앞에 붙은 이 슬래시( / )는 어떤 뜻일까? ▼

이는 Derived Attribute로 상속받은 변수라고 보면 된다.
밑줄 (_) : Class Scope Attribute
밑줄이 그어진 Attribute는 Class Scope Attribute이다. ▼

그런데 이거보다 많이 쓰는 표현은 Static Attribute이다.
Static을 사용하는 이유
중복되지 않게 변수를 설정하고 사용하려면 어떻게 해야할까?
하나의 값을 계속해서 사용하고, 그 값이 사라지지 않게 유지를 하면 된다.
그런데 지역 변수(Local Variable)들은 각자의 범위가 있어 그 범위가 끝나면 그 값이 사라지게 된다.
값을 유지하기 위해서는 매개변수나 반환 값으로 계속해서 그 값을 전달해야한다.
이를 한 번에 해결해주는게 하나 있는데, 바로 전역 변수(Global Variable)다.
전역 변수는 어디서나 접근할 수 있기에, 매개변수나 반환 값을 사용하지 않고 이름만 기억해두면 별도의 변수 생성 없이 사용할 수 있다.
그런데 전역 변수를 사용하는 것은 안좋다.
사실 안좋다라는건 꽤나 많이 봐준 표현이고 쓰지 않아야 한다.
이걸 쓴다는건 이 변수가 여기저기 다 얽혀있다는 뜻으로, 변수 하나에 의존성이 엄청나게 증가하게 된다.
만약에 전역변수 하나를 고쳐야하는 상황이 발생하게 되면 거기에 얽힌 모든 것을 바꿔야 한다.
OOP에서는 모듈화의 정 반대로 가는 것이다.
그러면 전역 변수는 절대 쓰면 안되는데 그럼 값을 어떻게 유지할까?
계속 전에 하던대로 매개변수에 전달하거나 반환 값으로 줘야할까?
이에 대한 해답이 바로 Static, Class Scope Attribute이다.
Static Attribute는 프로그램 시작할 때 클래스 하나당 하나만 만들고, 이 하나의 Attribute가 계속 유지된다.
해당 Static Attribute를 선언한 오브젝트들만 접근이 가능하기에 캡슐화도 깨지지 않고 값을 범위에 상관없이 유지하는 변수를 사용할 수 있게 된다.
그 외의 값들 표기
아래의 예시와 같이 추가적인 내용도 표기가 가능하다. ▼

Class Specification : Operations
클래스의 Operation을 표현할 때는 아래의 문법으로 표현한다. ▼
Operation name ‘(’parameter-list ‘)’‘:’ return-type-expression그런데 저기에 모든 operation을 표기하지 않는다. ▼
생성자와 소멸자가 없는 클래스는 없다.
따로 선언을 안했더라도 기본 생성자와 소멸자가 있기 때문에 모두가 생성자와 소멸자가 있다는 것을 안다.
이렇게 말 하지 않아도 모두가 아는 것들은 굳이 적지 않아도 된다.
그런데 생성자에 매개변수와 같은 특이 사항이 있으면 적어줘야한다.
getter와 setter도 마찬가지다.
Money에 직접 접근하면 안되니까, get이나 set을 통해 접근하는데 이는 attribute마다 있을 것이다.
그런데 이들이 있다는 사실을 모두가 알 것이고, 이를 작성하다보면 끝이 없기 때문에 작성하지 않는다.
Class Specification : Visibility
이제 attribute와 operation에 대해서 Visibility를 정해야한다.
Visibility는 우리가 흔히 사용하는 Public, Private과 같은 접근 권한이라고 생각하면 쉽다.
| Visibility symbol | Visibility | Meaning |
| + | Public | 레퍼런스만 있으면 다 접근가능 |
| - | Private | 내부에 있는 operation들만 접근가능 |
| # | Protected | 자기 자신과 서브 클래스들만 접근 가능 |
| ~ | Package | 패키지 단위로 접근 가 |

Attribute는 다 감춘다.
Operation들은 이미 그 Visibility(+, -)가 정해져있다.
"어디서 정해졌죠?"
앞에서 작성한 Communication Diagram에서 정해졌다.
거기에 작성한 Operation은 모두 Public Function들이고, 이 외의 Public Function은 작성되면 안되기에 나머지는 모두 Private Function으로 설정하면 된다.
이 함수들 내에서만 쓰는 함수는 전부 Private으로 설정하면 된다.
Criteria for Good Design
그렇다면 어떤 디자인이 좋은 디자인일까?
어떤게 좋은 건지 모르면 디자인의 방향성이 없이 그저 제자리만 빙글빙글 돌게 된다.
그렇기에 그 ‘좋음’에 대한 기준을 잡고 가야한다.
Coupling (의존성)
Coupling은 두 객체가 어느정도 붙어있는지를 말하는 것이다.
‘두 객체의 Coupling이 높다’라는 말은 ‘두 객체의 의존성이 높다’는 말과 같은 말이다.
그렇기에 Coupling은 낮아야 한다. ▼

Coupling의 기준
A 오브젝의 B 오브젝의 메세지를 전달한다는 말은 A가 B의 함수 호출한다는 말과 같다.
그렇기에 파라미터의 수와 전달하는 메세지 타입의 수를 합친게 coupling이라고 볼 수 있고, 이게 최대한 줄어야 Coupling이 낮다고 할 수 있다.
모델링의 원칙인 ‘인터페이스의 숫자를 최소화 해야한다’는 말이 바로 이 말이다.
Cohesion (응집력)
Design Element들은 Cohesion(응집력)이 높아야 한다.
Design Element는 하나의 목적만 가지고 있어야 한다.
Operation도 목적은 하나여야 한다.
하나의 목적을 두고 그 목적에 맞는 일을 해야한다.
Student라는 클래스가 있다고 하면, Student와 관련된 것들만 있어야하고, 그걸 보는 사람들도 그렇게 예상을 하고 있다.
Student와 어울리지 않는 그런 기능이 들어가 있으면 통일성이 없고, 응집력이 약하다고 볼 수 있다.
Class/Operation Cohesion
Cohesion의 핵심은 결국 한 가지 일만 하라는 것이다.
아래의 구조를 보자. ▼

Lecturer라는 클래스에 lecturerName, lecturerAddress가 있고,
추가로 roomNumber, roomLength, roomWidth가 있다.
강사 클래스에 강의실 정보가 필요하긴 할 수 있으니 엄청 이상하다고는 못하겠지만, 이 클래스가 한 가지 정보만 담고 있냐는 질문에는 확실하게 아니라고 답할 수 있다. ▼

그렇기에 Lecturer 클래스는 Cohesion이 떨어진다고 할 수 있다.
그에 비해 Operation은 Cohesion이 높다.
`calculateRoomSpace()` 라는 Operation은 오로지 방 넓이에 대한 값만 반환한다.
이런 측면에서 Operation Cohesion은 높다고 할 수 있다.
그러면 위의 Lecturer 클래스를 Cohesion이 높게 고쳐보면 아래와 같이 된다. ▼

이렇게 쪼개면 Lecturer의 cohesion도 높아지고, 새롭게 생긴 클래스인 Room의 cohesion도 높아지게 된다.
그런데 문제가 하나 발생하게 된다.
Cohesion이 높아진건 좋은데, 원래의 의도를 살릴 수 없게 된다.
원래의 의도를 보면 lecturer가 저 방에서 일하고 있음을 나타내는데 이렇게 나눠 버리면 그 관계를 표현할 수 없게 된다.
그래서 둘의 연결 관계도 만들어줘야한다.
Lecturer에서 Room으로, works at으로 연결이 필요하다. ▼
(삽화자리)
관계를 만들었으니, 이제 몇 대 몇 관계인지도 작성해줘야 한다.
여기서 끝이 아니다. 몇 대 몇인지 알아보자.
한 강의실에 0명부터 3명의 강사가 일을 한다고 하자.
그러면 Lecturer 0..3, Room 1 이 되며, Lecturer는 Room에 대한 레퍼런스만 가지게 된다. ▼
만약에 Cohesion이 낮게 유지가 되어있었다고 하면, Room 정보가 각 강사당 하나씩 들어가게 되어 3개가 될 수 있다.
게다가 Room 정보가 바뀌게 되면 3번의 정보 변경도 같이 진행이 되어야 한다.
데이터 중복과 유지보수 측면에서 현재가 더 좋은 방법이 된다.
Inheritance Degree
상속은 부모클래스의 것을 전부 자식클래스에 넘기는 것이다.
그런데 상속 받는 클래스가 부모 클래스의 것이 필요 없다면 이는 좋은 구조라고 하기 힘들다.
이런 구조가 있다고 해보자. ▼
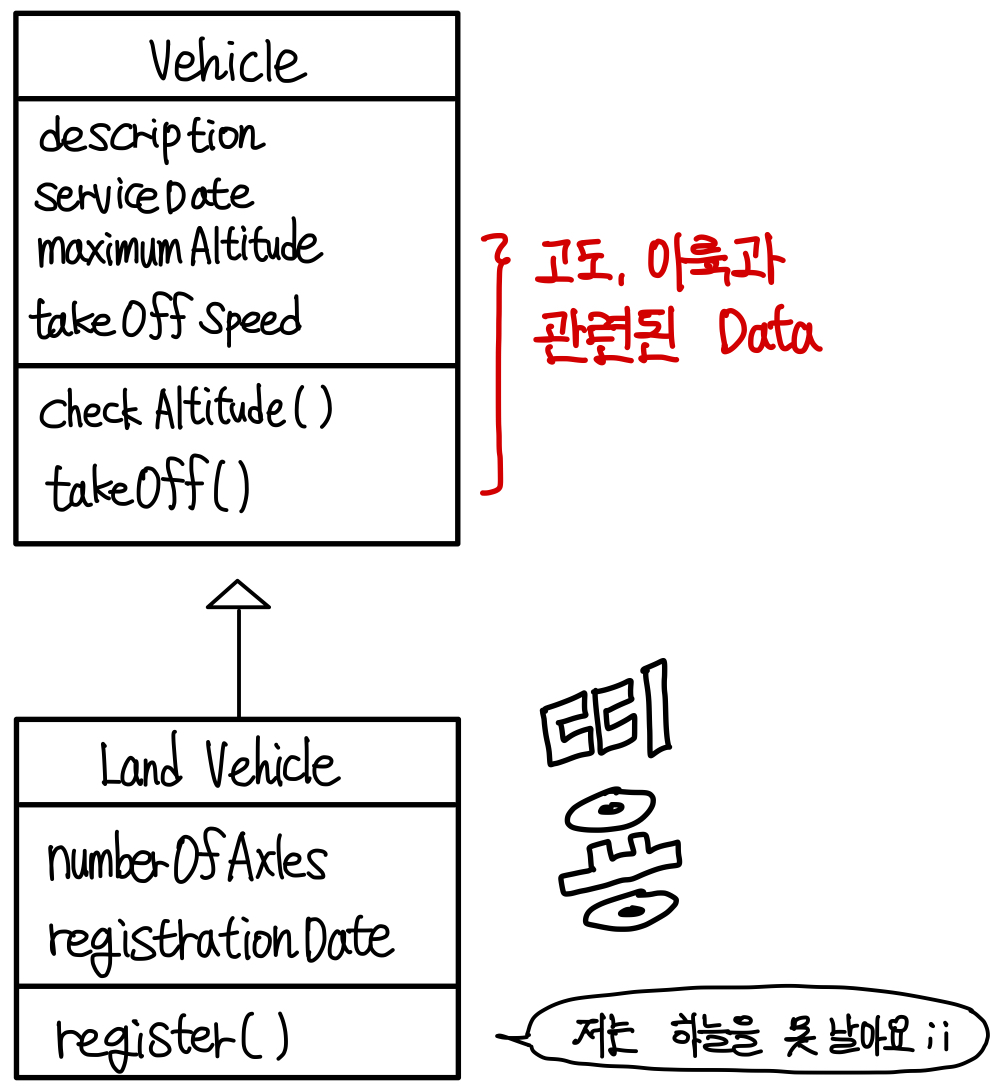
LandVehicle에 필요없는 Attribute와 Operation이 무려 4개나 있다.
그래서 4개를 SkyVehicel이라는 서브 클래스를 만들어 거기에 넣어준다. ▼

IS-A와 HAS-A
상속이 효율적인 것은 맞지만, 항상 효율적으로 동작하는 것은 아니다.
아래와 같은 관계를 보자.
Address(주소 클래스)를 Person(사람 클래스)과 Company(회사 클래스)가 상속을 받고 있다. ▼
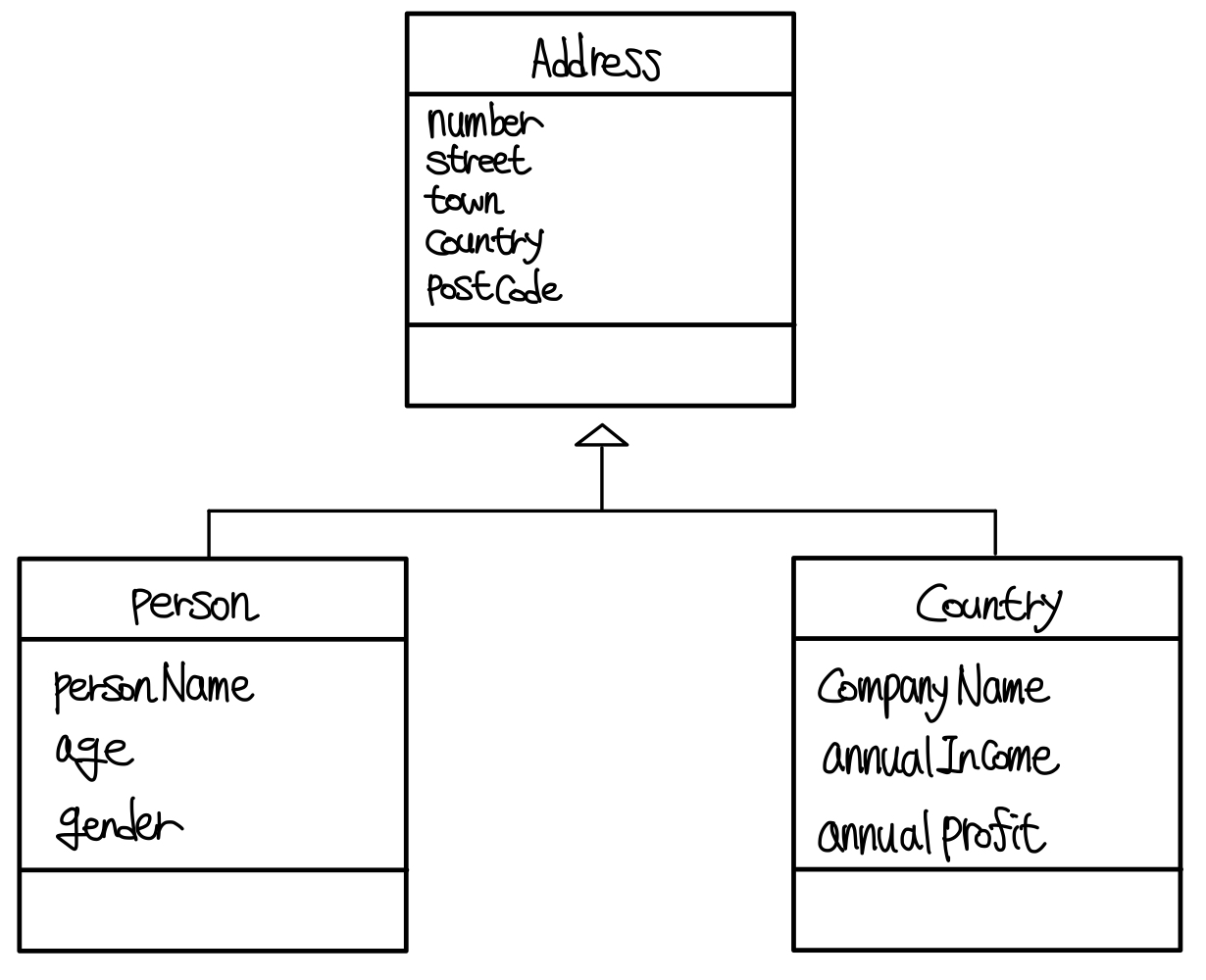
사람 클래스와 회사 클래스에 주소 정보가 있다는 것에는 전혀 이상함이 없으니, 두 클래스에 주소 클래스의 Attribute들이 존재하는 것에도 딱히 반박할 것은 없다.
"하지만 주소를 구체화 시킨다고 사람이나 회사가 될까?"
현실세계에서의 법칙을 생각해보면 이는 많이 이상하게 느껴진다.
주소는 사람과 회사가 ‘소유’하는 것이지, 사람이나 회사의 근본이 되는 것은 아니기 때문이다. ▼

그렇기에 주소 클래스와 사람, 회사 클래스의 관계는 IS-A가 아니라 HAS-A가 조금 더 이해하기 쉽다. ▼
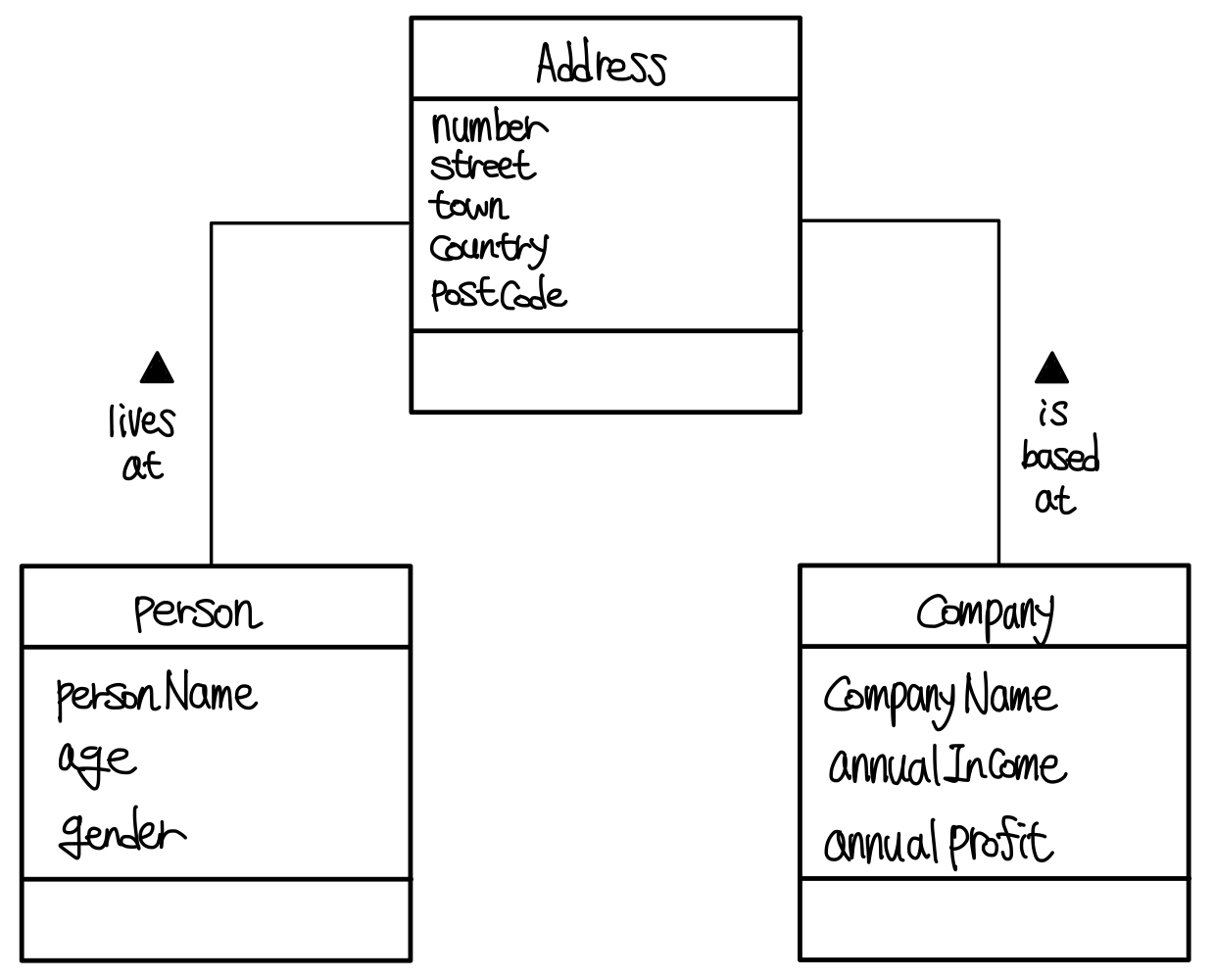
Attribute들을 받아온 결과만 보면 둘이 크게 다르지는 않다.
오히려 IS-A로 쓴게 조금 더 보기 쉬울 수도 있다.
하지만 이를 이해하는 과정과 현실세계의 묘사를 생각했을 때는 HAS-A가 더 보기 쉽다.
이렇듯 단순히 코드를 작성하는 것 뿐만 아니라, 그 코드를 이해하기 쉽게 문맥을 제공하는 것도 필요하다.
Designing Associations
앞에서 클래스 자체의 디자인에 대해서 알아보았는데, 이제는 Class/Operation Cohesion 주제에서 다뤘던 연결 관계에 대해서 알아볼 차례이다.
Association
우선 Association이란 무엇일까?
“그냥 둘이 연결된 거를 Association이라고 하는 거잖아요?”
…라고 할 수 있지만 약간의 차이가 있다.
먼저 두 객체를 연결하는 이유는 Message Passing을 하기 위함이다.
그리고 Message Passing을 위한 연결 관계는 Link라고 이야기 한다.
(한국어로도 연결이지만, Association과 구분을 조금 더 쉽게 하기 위해 영어로 부르겠다.)
"이미 Link라는 용어가 존재하면 Association이라는 표현은 왜 있는 걸까?"
이는 Association이 우리가 생각하는 연결과 미묘한 뜻의 차이가 있기 때문이다.
Association은 연결관계를 말하는 것이 아니라, 두 객체 사이에 있을 연결의 가능성을 말하는 것이다.
쉽게 말해 있을 수도 있고, 없을 수도 있음을 말하는 것이다.
현실 세계에서도 무언가에 대해서 단정지을 수 없을 때가 있다.
모든 사람이 차를 1대만 소유한다고 단정지을 수 있을까?
1대도 소유하지 못할 수도 있고, 100대를 소유한 사람이 있을 수도 있다.
이런 현실 세계의 객체들을 코드로 옮긴다고 하면, 차와 관련된 객체는 몇개를 두어야 할까?
일반적으로 1대에서 2대 정도를 가지니, 2개 정도를 둘까?
그렇다면 100대를 가진 사람은 코드에서 표현이 안되는 상황이 발생한다.
그렇다고 100대로 두자니 1대만 가진 사람이 많아 메모리 낭비가 발생한다.
현실은 확정지을 수 없는 것들 투성이니, 이를 Association을 통해 가능성을 표시한 것이다.
Association to Code
그렇다면 Associaition을 어떻게 코드로 바꿀까?
one-way one-to-one
아래의 예시는 주인이 차를 소유한다는 것을 나타낸다.
여기서는 차를 단 한 대만 가진다고 가정한다. ▼

차를 가지고 있다는 관계를 나타내기 위해 주인 클래스의 Attribute로 차 클래스를 넣어놓았다.
여기까지는 이상한 부분도 없고 오히려 타당하다.
그런데, 주인 클래스의 인스턴스가 엄청나게 많다면 어떨까?
주인 클래스에 차 정보를 다 넣어버리게 되면, 주인 클래스의 인스턴스 수 만큼 데이터가 중복된다.
현대 흰색 소나타를 가진 사람이 세상에 3명 정도만 있는게 아닐테니 말이다. ▼

그래서 공통된 것을 하나만 만들어버리고, 그 객체를 가리키는 포인터만 넣어주는 방식으로 효율적인 구성을 할 수 있다. ▼

Two-way association
Two-way association을 위의 예시로 보면 car도 오우너에게도 메세지를 보낸다는 것이다.
car가 오우너의 오브젝트 레퍼런스를 가지면 된다.
근데 two-way는 coupling이 굉장히 높아지기에 의존성을 줄이기가 힘들어진다.
그래서 최대한 적게 만드는 것을 권장한다.
One-to-many
여러 개를 모음이라는 단어로 Aggregation이라고 표현을 하며, 이는 다이아몬드 모양의 기호로 표현한다. ▼

one to many는 레퍼런스를 리스트로 가지게 된다.
1 대 1일 때는 참조 하나만 정의해주면 그만이지만, 리스트인 경우에는 리스트를 관리하는 operation도 필요해진다.
연결리스트를 구현할 때 추가, 제거, 찾기의 operation들이 필요한 것처럼, 리스트를 관리하는 operation 추가를 해야한다.
그런데 그렇게 리스트 관리 Operation들이 들어가게 되면 해당 클래스와 어울리는지는 또 다른 문제이다.
Campaign이 Advert의 리스트를 갖는다고 해보자.
그러면 Advert리스트와 관련된 Operation인 addAdvert()와 deleteAdvert()와 같은 함수들을 구성해야하는데, 이 함수들이 Campaign 자체와 어울리는지는 별개의 문제라는 것이다.
사실 Cohesion이 조금 낮아도 구조를 짜는데와 코드가 돌아가는데에는 문제가 없지만, 웬만하면 그 코드를 읽는 사람의 이해도를 높여주는게 좋다.
어쨌든 간에 협력해야하기 때문이다.
그렇게 하기 위해서는 다른 클래스로 분리하는게 좋을 것이다. ▼

Collection Class
Advert의 리스트와 관련된 요소를 분리한 것을 Collection Class라고 한다.
이 클래스는 Advert의 집합만을 관리한다.
이렇게 분리하는 편이 코드를 이해하는데 좀 더 수월하다. ▼

Many-to-many
many to many가 되면 아래와 같이 된다. ▼

'CS > 소프트웨어 공학' 카테고리의 다른 글
| 17. State Machine (0) | 2024.02.03 |
|---|---|
| 16. Designing Boundary Classes (작성중) (0) | 2024.02.03 |
| 14. Sequence Diagram (작성중) (0) | 2024.02.03 |
| 13. Use Case Realization (0) | 2024.01.31 |
| 12. Configuration and Version Management (0) | 2024.01.31 |



